Fooling the Detector, Adversarial Attacks on Fake News Models
Spring 2026 CSCI 5541 NLP: Class Project - University of Minnesota
NLP5541
Jason Wang
Cheng-Fu Tseng
Shretij Kapoor
Jason Wang
Cheng-Fu Tseng
Shretij Kapoor
Fake news detection models are widely used, but they often rely on superficial patterns rather than true semantic understanding, making them vulnerable to subtle input changes. In this project, we benchmark three models—Plain RoBERTa, SheepDog, and our Enhanced Model—on the PolitiFact dataset to evaluate both standard performance and robustness under perturbed inputs. While SheepDog achieves the highest clean accuracy, our Enhanced Model shows the strongest robustness, with the smallest performance drop under input variations.
This figure illustrates how small, meaning-preserving changes to news text can significantly alter model predictions, highlighting the robustness gap between models.

We compare three fake news detection models under both clean and perturbed evaluation settings to understand the tradeoff between accuracy and robustness.
What did you try to do? What problem did you try to solve?
We aim to evaluate how reliable fake news detection models are when the input text is slightly modified without changing its meaning. In real-world scenarios, malicious actors can rephrase or restyle content to evade detection systems, so robustness is just as important as accuracy.
How is it done today, and what are the limits of current practice?
Most fake news detection systems are built using large pre-trained language models such as RoBERTa and are evaluated primarily on clean datasets. However, these models often rely on surface-level statistical cues such as writing style or word frequency. As a result, even small, meaning-preserving changes can cause significant drops in performance.
Who cares? If you are successful, what difference will it make?
Improving robustness in fake news detection is critical for real-world deployment. More reliable models can better withstand adversarial manipulation, helping platforms and users identify misleading content more effectively.
What did you do exactly? How did you solve the problem? Why did you think it would be successful? Is anything new in your approach?
We implemented and compared three models on the PolitiFact dataset: (1) a Plain RoBERTa baseline, (2) SheepDog, a literature-based model designed to improve robustness through reframing consistency and auxiliary supervision, and (3) our Enhanced Model, which incorporates multiple robustness techniques including adversarial training (FGSM), R-Drop regularization, consistency training on augmented inputs, and fine-grained auxiliary supervision.
All models were evaluated on both clean test data and a perturbed/restyled version of the dataset to simulate distribution shifts and robustness challenges.
What problems did you anticipate? What problems did you encounter? Did the very first thing you tried work?
We anticipated challenges in ensuring fair comparisons across models and maintaining stable training when combining multiple loss components. In practice, we encountered issues such as dependency conflicts, dataset handling inconsistencies, and instability when integrating adversarial training. Additionally, some experiments on extended datasets were incomplete due to runtime issues. Initial baseline models trained successfully, but achieving robustness required more sophisticated techniques and tuning.
How did you measure success? What experiments were used? What were the results? Did you succeed?
We evaluated model performance using accuracy and macro F1-score on both clean and perturbed (restyled) test sets. This allowed us to measure not only standard classification performance but also robustness under input variation.
| Model | Clean Accuracy | Clean F1 | Perturbed Accuracy | Perturbed F1 | F1 Drop |
|---|---|---|---|---|---|
| Plain RoBERTa | 0.8889 | 0.8884 | 0.7889 | 0.7882 | 0.1002 |
| SheepDog | 0.9444 | 0.9444 | 0.8111 | 0.8111 | 0.1333 |
| Enhanced Model (Ours) | 0.9000 | 0.8997 | 0.8222 | 0.8222 | 0.0775 |
SheepDog achieved the highest performance on clean data, indicating strong in-distribution accuracy. However, our Enhanced Model demonstrated the best robustness, achieving the highest performance on perturbed inputs and the smallest drop in F1 score. This suggests that our approach better generalizes under input variation, which is critical for real-world deployment.
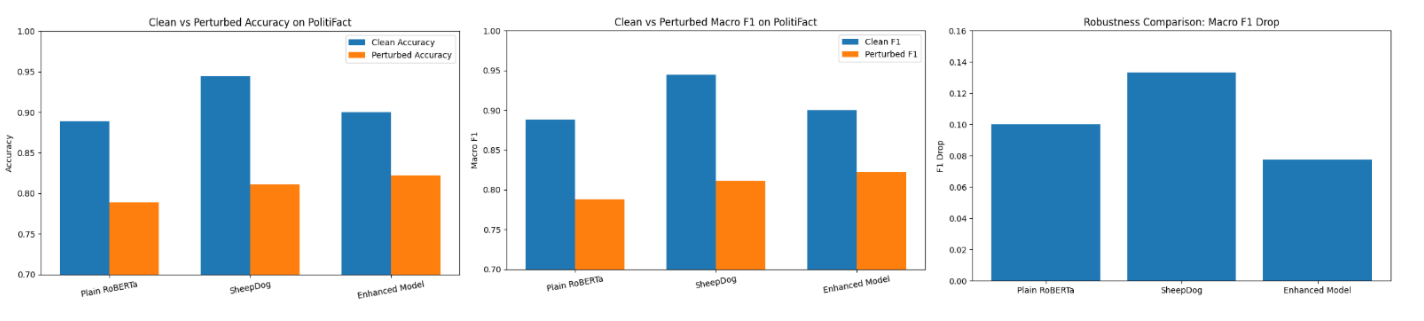
Our results show a clear tradeoff between clean accuracy and robustness. While SheepDog performs best on standard benchmarks, our Enhanced Model is more stable under perturbed inputs, making it a promising direction for robust fake news detection.
Currently, our evaluation uses restyled or perturbed variants of the dataset as a proxy for adversarial inputs. In future work, we plan to generate our own adversarial datasets using character-, token-, and sentence-level perturbations to better simulate real-world evasion strategies.
Our work is partially reproducible using the provided training pipelines and publicly available datasets, though improvements such as multi-seed evaluation and standardized hyperparameters are needed for stronger reproducibility.
Potential risks include misuse of adversarial techniques to intentionally evade detection systems. To mitigate this, our focus is on improving model robustness rather than enabling attacks.
Future extensions include expanding to additional datasets, improving adversarial generation methods, and analyzing model failures to better understand linguistic vulnerabilities.